Prompt Engineering
DAIR.AI에서 제공하는 Prompt Engineering Guide 공식 문서를 보면서 공부하였다.
Claude에서 제공하는 Anthropic 공식 문서도 같이 보면 좋은 듯!!
Prompt Engineering Techniques
Zero-shot Prompting
Prompt:
Classify the text into neutral, negative or positive.
Text: I think the vacation is okay.
Sentiment:
Output:
Neutral
가장 기본적인 형태의 프롬프트이다. 일상적으로 ChatGPT를 사용할 때, “정렬 알고리즘에 대해 알려줘”, “갈비찜 레시피 알려줘”와 같은 오직 질문만으로 프롬프트가 구성된다.
따라서, Zero-shot 에서 shot 은 ‘답변 예시’의 개수를 의미한다고 볼 수 있다.
Few-shot Prompting
Prompt:
This is awesome! // Positive ^^
This is bad! // Negative ㅜㅜ
Wow that movie was nice! // Positive ^^
What a horrible show! //
Output:
Negative ㅜㅜ
Few-shot , 즉 여러개의 질문-답변 쌍을 예시로 제공하여 답변의 가이드를 제공함으로써 원하는 답변을 유도하는 기법이다. Zero-shot에서는 위 예시와 같이 ^^ 나 ㅜㅜ를 출력에 포함시킬 수 없었을테지만, 예시 답변을 작성함으로써 원하는 결과를 얻을 수 있었다.
문서 에서 Label(Positive 또는 Negative)를 randomly assign해도 도움이 된다는 내용이 언급되었는데, 꼭 그런건 아닌 것 같다. 실제로 해보면 Randomness를 학습해서 아무 output이나 내뱉기도 하고, gpt-4o 같은 경우는 Prompt의 잘못된 점을 지적하기도 한다.
Prompt:
This is awesome! // Negative
This is bad! // Positive
Wow that movie was rad! // Positive
What a horrible show! //
Output(gpt-4o):
It looks like there might be some confusion in your examples regarding the sentiment classification. Here is the corrected sentiment classification:
- "This is awesome!" // Positive
- "This is bad!" // Negative
- "Wow that movie was rad!" // Positive
- "What a horrible show!" // Negative
Would you like any further help with sentiment analysis?
수학적 규칙을 찾는 Reasoning Problem에 있어서는 Few-shot Prompting의 성능이 다소 떨어진다고 한다. 사실 문서 의 예시로 테스트를 해보면 그 새 모델의 추론능력이 발전해서인지 잘 풀긴 하는데… 아무튼 그렇다고 한다. 이러한 Reasoning Problem은 ‘풀이과정’이 중요하기 때문에, 대안으로 Chain-of-Thought Prompting이 제시된다.
Chain-of-Thought Prompting (CoT)
Chain-of-Thought (CoT)
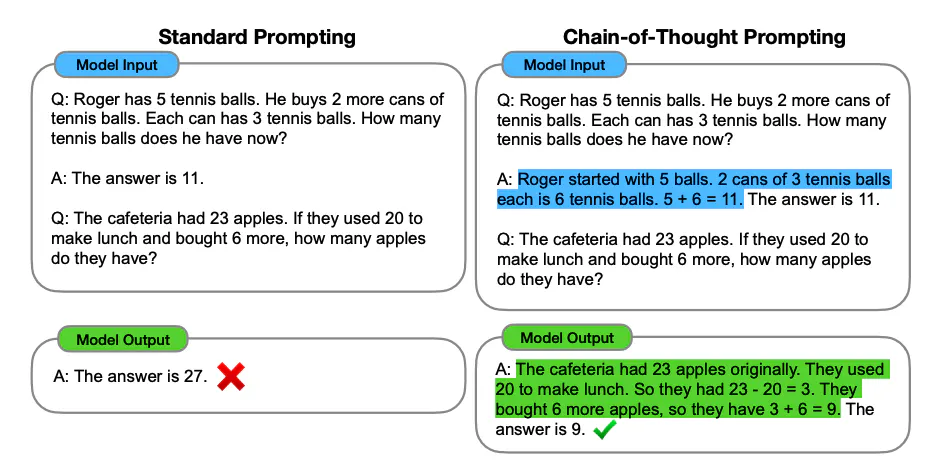
Image Source: Wei et al. (2022)
Chain-of-Thought(이하 CoT)의 개념은 간단하다. Few-shot Prompting의 shot이 기존에는 ‘질문-답변’ 이었다면, CoT는 shot을 ‘질문-(풀이과정 + 답변)’으로 구성함으로써 원하는 답변을 유도한다.
그리고!!! CoT에서 이러한 ‘풀이과정’을 »Rationale« 라고 말하는 것 같음! 또는 »Reasoning Path« 용어 숙지는 항상 중요하다~
Zero-shot CoT

Image Source: Kojima et al. (2022)
CoT는 훌륭한 기법이지만, Few-shot을 생성하는 일은 번거롭고 Prompt 길이를 과도하게 증가시킨다. Zero-shot-CoT는 예시들을 제공하지 않고도 LLM이 풀이과정과 답을 같이 제공하도록 유도한다.
A: Let's think step by step 으로 Answer의 서두를 미리 작성하면, 이 다음 문장을 완성해야하는 LLM 입장에서는 바로 답을 내는 것 보다 풀이과정들(step by step)을 먼저 쓰고, 답을 내리는 것이 자연스러울 것이다.
Few-shot CoT는 유사한 문제들에 대해서 풀이 과정을 이미 알고 있어야 한다는 전제가 붙는데, Zero-shot CoT는 그렇지 않은 상황에서도 CoT를 보여줄 수 있다는 장점이 있다고 보인다(내 생각).
Automatic Chain-of-Thought (Auto-CoT)

Image Source: Zhang et al. (2022)
Auto-CoT의 개념은 다소 복잡하지만, 2개의 가정을 깔고 가면 비교적 쉽게 이해할 수 있다고 생각한다.
- Zero-CoT에서 “Let’s think step by step”으로 생성한 Rationale + Answer는 틀린 답을 내놓을 때도 있다.
- 그러한 틀린 답을 발생시키는 Question들은 유사성을 가지고 있어 Clustering 될 수 있다.
Auto-CoT의 개략적인 컨셉은 Zero-shot CoT를 통해 Qustion-(Rationale+Answer) 쌍을 여럿 만들고(이를 Demos라 한다.) Demos를 이용하여 Few-shot CoT를 수행하는 것으로 요약된다.
이때, Demos를 만들기 전에 Question들을 k개의 클러스터로 나누는 과정이 선행된다. 여기에서 우리의 2가지 가정에 따라 k개의 클러스터 중 하나에 “틀린 답을 발생시키는 Question”들이 모두 모이게 된다.
Demos는 각 클러스터에서 대표 Question을 하나씩 뽑아 쓰므로, Demos에는 총 k개의 Qustion-(Rationale+Answer) 쌍이 있고 그 중 하나는 “틀린 답을 발생”시키고 있을 것이다.
그 말은 반대로, k-1개의 쌍은 적절한 답변을 발생시키고 있으며, 만약 k=8 이라면 87.5%의 정확도를 가지는 Few-shots를 제공하는 CoT를 수행하는 결과를 만들어낼 수 있다.
기본적으로 LLM은 Prompt가 구체적일수록 정확한 답변을 내기 마련이다. 그러므로 제공되는 Rationale들이 적합하기만 한다면 Few-shot CoT는 통상적으로 Zero-shot CoT보다 우수한 성능을 보일 것이다. 하지만 Shots를 미리 작성하는 것은 번거롭고 매뉴얼하기 때문에, Auto-CoT는 이를 절충하여 자동으로 Few-shot CoT를 수행할 수 있는 방법을 고안했다고 볼 수 있다. 다만 그러한 Automation에 따라 1/k 만큼의 correctness는 trade-off되는게 아닌가 싶다.
Self-Consistency
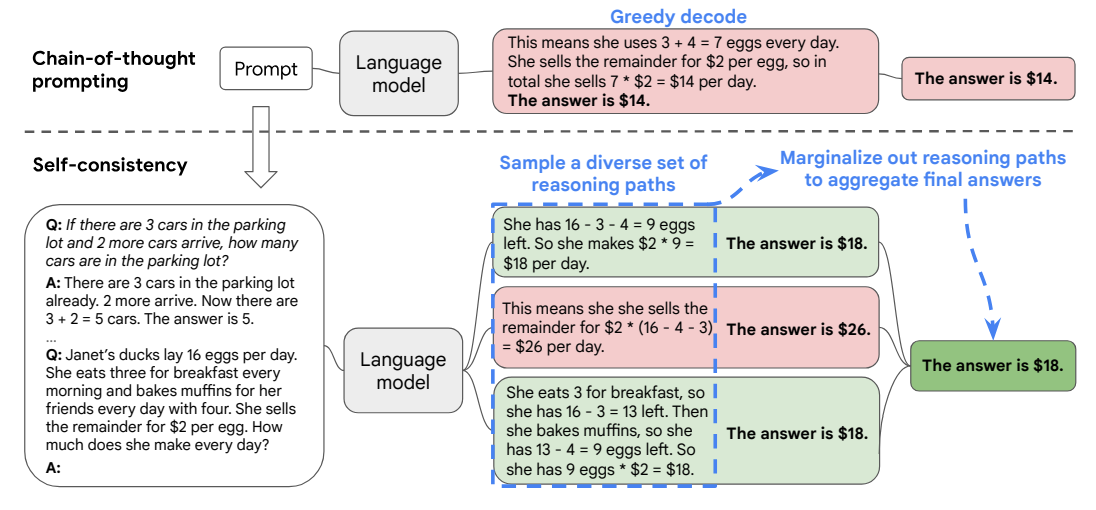
Image Source: Wang et al. (2022)
Self-Consistency는 간단히 말해서, LM으로 복수개의 답변을 생성한 후에 그들 중에서 다수결로 최종 답변을 정하는 방식이다.
최종 답변을 정하는 방법을 Aggregation Strategy라 하고 그 중에 단순히 다수결로 정하는게 Majority Vote이고, 기타 방법들이 더 있는 것 같은데 굳이 알 필요는 없을 것 같다(성능이나 생산성 측면에서 우수하지 않아보임).
Generate Knowledge Prompting
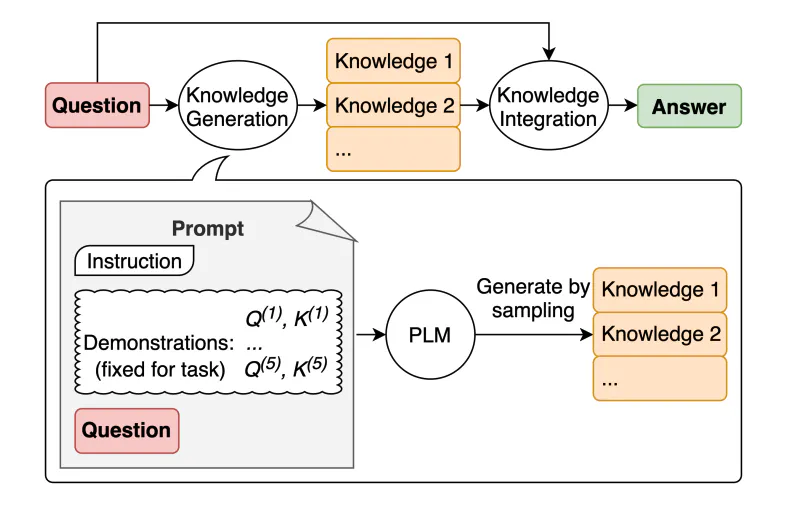
Image Source: Liu et al. (2022)
Generate Knowledge Prompting 은 문자 그대로, Prompt에 Genrated Knowledge를 같이 끼워 넣음으로서 답변의 질 향상을 도모하는 기법이다. Generation도 물론 LM이 수행한다.
이때, Knowledge Generation을 Zero-shot Prompting으로도 할 수 있지만, “특정 질문에 대답하는 도움이 되는” Knowledge를 생성하기 위해서는 일정한 가이드가 필요할 수 있으므로, 해당 논문에서는 Few-shot Prompting을 사용한 듯 하다.
즉, 1회 답변을 위해 2회의 LM 사용이 있다고 볼 수 있으며 예시 프롬프트는 아래와 같다.
Prompt(Knowledge Generation):
Input: Greece is larger than mexico.
Knowledge: Greece is approximately 131,957 sq km, while Mexico is approximately 1,964,375 sq km, making Mexico 1,389% larger than Greece.
Input: Glasses always fog up.
Knowledge: Condensation occurs on eyeglass lenses when water vapor from your sweat, breath, and ambient humidity lands on a cold surface, cools, and then changes into tiny drops of liquid, forming a film that you see as fog. Your lenses will be relatively cool compared to your breath, especially when the outside air is cold.
Input: A fish is capable of thinking.
Knowledge: Fish are more intelligent than they appear. In many areas, such as memory, their cognitive powers match or exceed those of ’higher’ vertebrates including non-human primates. Fish’s long-term memories help them keep track of complex social relationships.
Input: A common effect of smoking lots of cigarettes in one’s lifetime is a higher than normal chance of getting lung cancer.
Knowledge: Those who consistently averaged less than one cigarette per day over their lifetime had nine times the risk of dying from lung cancer than never smokers. Among people who smoked between one and 10 cigarettes per day, the risk of dying from lung cancer was nearly 12 times higher than that of never smokers.
Input: A rock is the same size as a pebble.
Knowledge: A pebble is a clast of rock with a particle size of 4 to 64 millimetres based on the Udden-Wentworth scale of sedimentology. Pebbles are generally considered larger than granules (2 to 4 millimetres diameter) and smaller than cobbles (64 to 256 millimetres diameter).
Input: Part of golf is trying to get a higher point total than others.
Knowledge:
Output(Knowledge Generation):
The objective of golf is to play a set of holes in the least number of strokes. A round of golf typically consists of 18 holes. Each hole is played once in the round on a standard golf course. Each stroke is counted as one point, and the total number of strokes is used to determine the winner of the game.
Prompt(Knowledge Integration):
Question: Part of golf is trying to get a higher point total than others. Yes or No?
Knowledge: The objective of golf is to play a set of holes in the least number of strokes. A round of golf typically consists of 18 holes. Each hole is played once in the round on a standard golf course. Each stroke is counted as one point, and the total number of strokes is used to determine the winner of the game.
Explain and Answer:
Output(Knowledge Integration):
No, the objective of golf is not to get a higher point total than others. Rather, the objective is to play a set of holes in the least number of strokes. The total number of strokes is used to determine the winner of the game, not the total number of points.
Prompt Chaining
고객으로부터 서류를 메일로 받아 검토하고, 이에 대한 의견서를 작성하는 업무를 하는 상황을 생각해보자. 이 업무를 위해 우리는 (1) 서류를 읽고 중요 사항을 파악하고, (2) 중요하다고 생각되는 부분들에 대해 의견을 작성하며 (3) 메일을 보내기 전에 한 번 상사의 리뷰를 받는 과정을 거칠 수 있다. 이처럼, “오늘 서울의 날씨는?”, “3*4+5의 답은?” 같은 단순한 문제를 풀 때와 달리 문제가 복잡해지면 업무를 쪼개서 처리하곤 한다.
LLM을 이용해 법률문서 작성, 진단서 작성 등 복잡한 업무를 수행할 때에도 이처럼 단계를 나누어서 문제를 해결하는 것이 요구된다. 이때 각 단계별로 전 단계의 Output이 다음 단계의 Prompt로 제공될 것이고, 각 Step의 Output과 Input(Prompt)가 체인처럼 이어지는 모양을 띠기 때문에 이 러한 기법은 Prompt Chaining이라고 명명된다.
- Accuracy(정확성): Each subtask gets Claude’s full attention, reducing errors.
- Clarity(명확성): Simpler subtasks mean clearer instructions and outputs.
- Traceability(추적성): Easily pinpoint and fix issues in your prompt chain.
Prompt Chaining은 긴 설명보다 예제를 보는게 이해에 더 도움이 되었는데, Anthropic Chain Prompts 문서에 Self correcting, Analyzing Legal Contract에 대한 예제가 잘 나와 있어 이것으로 설명을 갈음한다.
Tree of Thoughts (ToT)
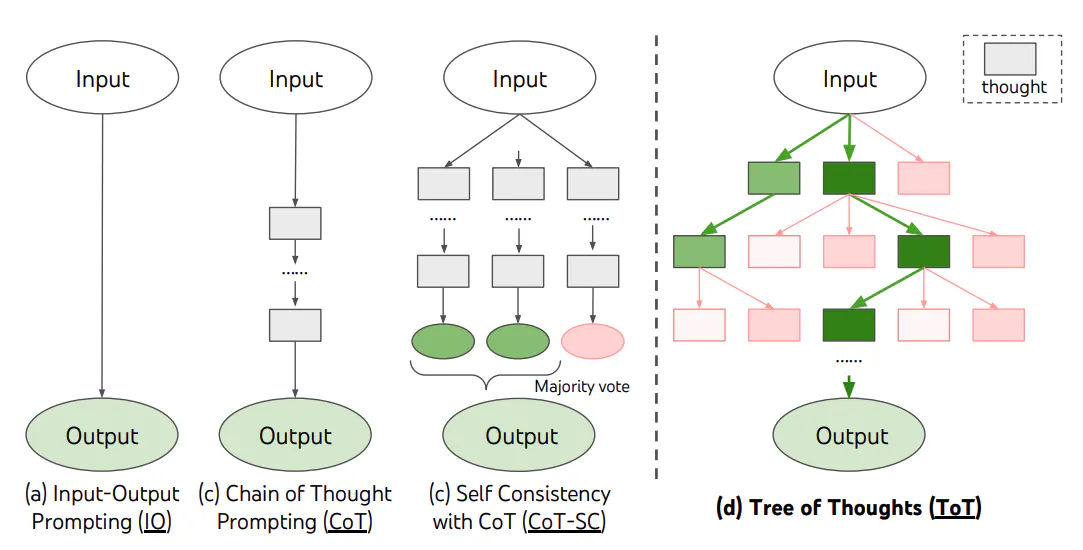
Image Source: Yao et al. (2022)
Self-Consistency를 확장하여, Reasoning path를 분설해서 하나의 트리로 만들고 BFS 등 탐색 알고리즘을 써서 최적의 답변을 만들어낸다는 개념이다.
아마 문제를 step-by-step으로 푸는게 상당히 중요한 상황에서 쓰일 것 같다(논문에서도 Game of 24 라는 숫자퍼즐을 대상으로 함). 또, ToT를 적용하려면 각 Step마다 현재 Goal을 향해서 잘 가고 있는지 측정할 수 있는 Measure가 있어야한다(논문에서는 남은 숫자들로 24를 만들 수 있는지 없는지 여부로 판단). 근데 그런 상황이 Game of 24 같은 특별한 경우 외에도 있는지와, 사실 그렇게 구조화해서 풀 수 있는 문제면 대부분 rule-base로 풀 수 있지 않을까 싶기도 하고… 아직은 잘 모르겠다~.~
Retrieval Augmented Generation (RAG)
Retrieval을 Search로 바꾸면 바로 이해될 수 있다. 검색이 가능한 ChatGPT라고 생각하면 된다. 그렇지 않아도 GPT-4o 버전부터나, 또는 그 전의 Bing Search에서 AI가 직접 검색을 하고 그 결과를 바탕으로 답변을 생성하는 모습을 볼 수 있었다. 이처럼 LLM이 자기 안에 내장된 지식과 더불어 검색을 통해 외부 데이터도 활용하여 최신의 풍부한 답변을 제공하는 기법이라 할 수 있다.
dair-ai Github Repo 에 관련 예제가 있다.
김영욱님의 10분 만에 RAG 이해하기 도 RAG를 이해하는데 도움이 되었다.
그렇다면, LM이 어떻게 검색을 해서 답변을 생성하는 걸까? LM이 직접 구글에 질문을 검색해서 찾는다고 생각하면 곤란하다. AI가 사람 같긴해도 어디까지나 프로그램이기에, 프로그램으로서 수행딜 수 있는 프로세스로 구현되어야 한다.
원하는 데이터를 검색하기 위해서는 Embedding된 형태의 ‘지식 컨텐츠 저장소’가 있어야 한다. 이해를 위해 한 가지 문제를 상정해보자.
“SK 와이번스-SSG 랜더스의 포수 중 한국시리즈 우승에 가장 공헌도가 큰 선수의 선수 경력을 요약해줘.” 라는 질문에 대해 LM이 답을 해야하는 상황이다. 우리에게 주어진 자료로는 역대 KBO 모든 선수들에 관한 위키피디아 문서 가 있다. 이때 RAG를 수행하는 프로세스는 아래와 같다.
- 위키피디아의 모든 문서들을 BERT 등 언어 모델을 이용하여 Embedding한다(문서를 하나의 다차원 벡터로 만듦을 의미). 이를 지식 컨텐츠 저장소라 하자.
- User로부터 Query를 받는다.
- Query는 SK 와이번스-SSG 랜더스의 포수, 한국시리즈 우승 따위가 될 수 있다.
- Query를 지식 컨텐츠 저장소에 입력하면 가장 연관성이 높은 K(ex. 10)개의 문서를 가져올 것이다.
- Query에 따라, 한국시리즈 우승 경험이 있는 SK-SSG의 포수들을 Retrieve할 확률이 제일 높을 것이다.
- (1) “SK 와이번스-SSG 랜더스의 포수 중 한국시리즈 우승에 가장 공헌도가 큰 선수의 선수 경력을 요약해줘.”, (2) Query, (3) 2. 에서 나온 K개의 문서를 합쳐서 하나의 Prompt로 만들어 LM에 입력하고 실행한다.
- LM은 한국시리즈 우승 경험이 있는 포수에 대한 정보들을 기반으로 답변을 생성하기 때문에, 신뢰성이 상당히 높은 답변을 출력할 수 있을 것이다.
Search가 아닌 Retrieval이라고 표현하는 이유는 양질의 Retriever를 개발하는 것도 RAG의 핵심 요소이기 때문이다. Retreiver는 저장된 정보 중 관련 있는 것을 가져오는 것뿐만 아니라, 그것을 가져오기 위해 적절히 임베딩된 데이터로 저장하는 것까지 포함하는, Search보다 기능적인 의미를 더욱 더 내포하고 있다고 볼 수 있다.
RAG는 최근 LLM 서비스의 핵심 기능으로 작동하며 이를 수월하게 구현하기 위해서 LangChain 등 Framework들도 개발되고 있다. 이와 관련해서는 김영욱님의 10분 만에 랭체인(LangChain) 이해하기 글이 이해에 도움이 되었다.